Extracting Audio Messages from WeChat
Want to skip the chatter and just find out how to extract and convert WeChat audio messages? Click here to skip to the instructions.
WeChat (Chinese: 微信, wěi xìn) is a chat app popular in mainland China and used by many Chinese immigrants around the world. It’s a staple in China as much as Facebook is here, being used by pretty much everybody who has a smartphone. It was also far ahead of introducing features that are now standard in most chat apps: things like stickers, “share” messages from other apps, and audio messages were present in WeChat long before they made their way to services like Facebook Messenger.
Audio messages in particular are an interesting case: because Chinese text input is more complicated than English, many Chinese people just prefer pushing a button and speaking a short message to their friends than trying to type it out. It allows for much quicker messaging when you’re on the move.
Recently, I found myself wanting to extract some WeChat messages from my chat logs for use in a personal project. The problem is, WeChat offers no opportunity for bulk exporting chat logs: the most you can do is email a small, hand-selected set of messages to yourself, and that only brings across text content. So I found myself realizing that if I was going to do this, I needed to do it myself.
The way I ended up doing it is by extracting WeChat’s data from my iPhone’s backup on my computer. This gave me access to an SQLite file that contained all the text content of my chats, a folder that contained all the images from those chats, another that contained all the video files, and so on.
Audio messages, though, were another beast, as they were kept in an undocumented format with the unusual extension of “.aud”. Searching online gave little illumination as to which type of format they use either, and no usable instructions for converting them into a more mundane format like mp3.
I didn’t let that stop me, though, and I managed to reverse-engineer the audio format that WeChat uses. Here, I’m presenting the steps, tools, and code that I used to convert them, in the hopes that they might be useful to other people in the future, as well as a description of the process I went through in trying to reverse-engineer their file format.
Extracting and converting WeChat audio messages
Before we get into the logistics of how this is done, I want to mention a few things about the instructions:
-
They are meant for technical users. You have to at least be comfortable with the command line and a C compiler.
-
These instructions are mainly focused on my own setup: using Mac OS X, iOS 9 and iTunes 12. If you’re using Windows, or if you’re reading this in the future with later versions of the software, you’ll have to adapt the instructions to your own system.
-
And speaking of you future visitors, these instructions are valid as of WeChat version 6.3.7, which is the current version as of the publication of this article. WeChat has already changed their audio format once, and nothing is stopping them from changing it again if they feel it’s necessary.
Let’s get on with it.
Extracting WeChat data from iOS
Plug your phone or tablet into your computer and open iTunes. You need to make sure that your phone is set to backup to your computer, and not to iCloud. If it’s backing up to iCloud, change the setting and sync your device. Make sure that encryption is turned off for your backup.
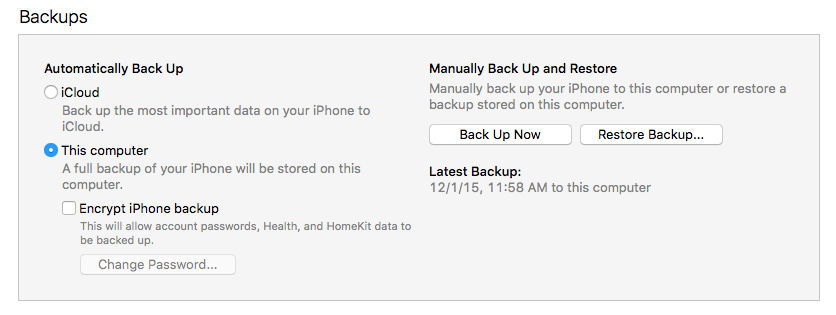
The relevant option in the iTunes device preferences.
This will create a backup of your phone onto your computer. The next step is to extract the WeChat data from this backup. For this, I used iExplorer. This is a paid app, but for our purposes you should be able to use the trial version, as you won’t need any of the advanced features.
Click on “Browse iTunes Backups” and look for the backup of your device in the left sidebar. Expand it and click on “Backup Explorer”, and in the file browser look for the folder called “App - com.tencent.xin”. Take this whole folder and drag it to your Desktop to export it.
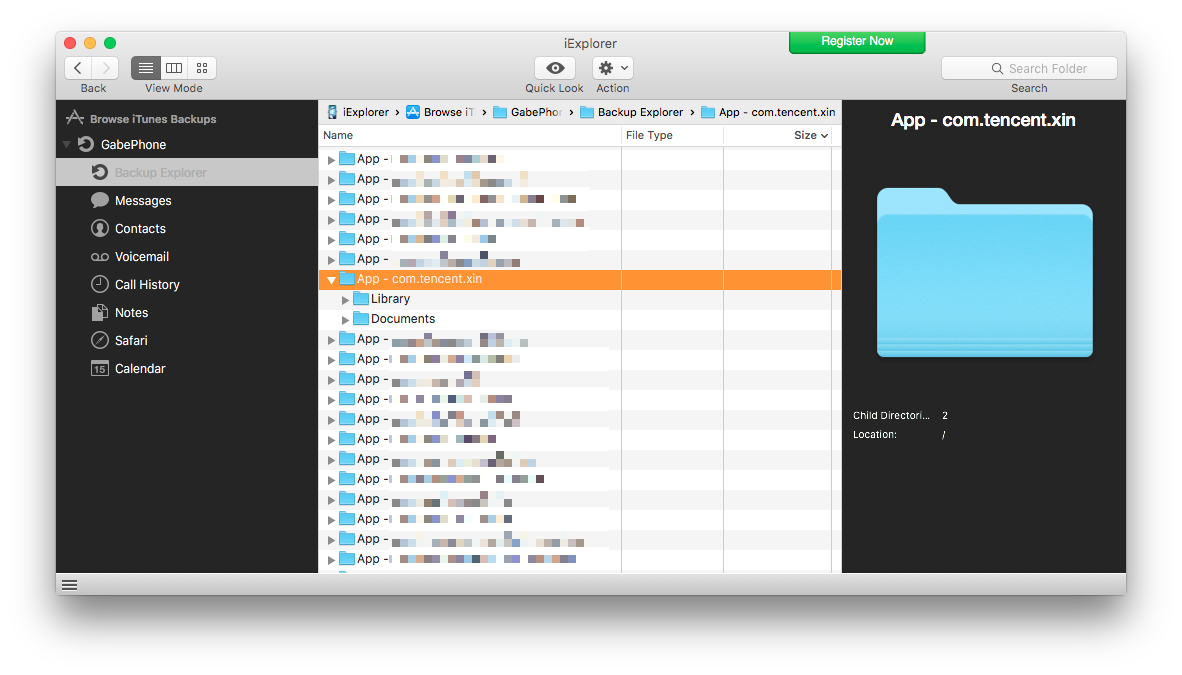
Inside this folder, you’ll find a folder called “Documents”. Open it, and look for a folder that has a whole bunch of random hex digits. Inside this folder, you’ll find the data for all your conversations. Audio data is, as expected, in the folder named “Audio”, and each folder underneath “Audio” is the data for a different conversation you’ve participated in, identified by a unique set of hex digits.
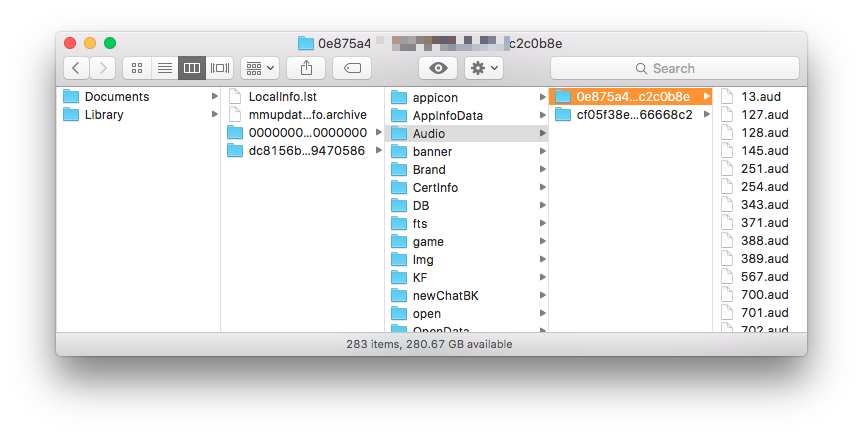
The .aud files inside each of the conversation folders are your audio files.
As an aside, there’s a lot more that you can extract from here:
-
The “Img” folder contains all the images you’ve sent and received in all your chats. The image files have a “.pic” extension but they’re really just renamed png files. You can open them by just changing their extension to “.png”.
-
The “Video” folder contains all videos and Sights you’ve sent and received, all in easy-to-open mp4 format.
-
Your text chat logs are stored in the SQLite database file at “DB/MM.sqlite”. These can be accessed with the command-line SQLite client or a graphical client like the SQLite Database Browser.
All of these use the same string of hex digits to identify each conversation, so looking through these can help you to figure out which folder under “Audio” is the conversation you want to convert.
Converting .aud files to .wav
In order to convert these files, you’ll need to gather a few dependencies first:
-
Download my conversion script from this Github link. Make sure you have Python 2.7 installed.
-
Install ffmpeg. On Mac OS X it’s available through Homebrew. ffmpeg is a command-line utility for working with audio files.
-
You’ll need some sort of C compiler for the next step. If you’re on a Mac, make sure you’ve got XCode and its command-line tools installed. On Windows, Visual Studio should work.
-
You’ll need a decoder for the SILK audio codec. You can download it from here. Get the whole repository as a zip, then build the version of the codec in the “SILK_SDK_SRC_ARM” folder:
On Mac: There’s a Makefile in the folder.
cdinto it, runmake libto make the SILK library, thenmake decoderfor the decoder program. You’ll end up with a library file called “libSKP_SILK_SDK.a” and a decoder executable just called “decoder”. For best results, copy these both into the same directory as the converter script.On Windows: If you can use a Makefile, you can follow the same instructions as on Mac. If not, you can also compile these with Visual Studio, by using the .sln file available in the same directory. You should end up with a library file (likely a .dll file) and a decoder executable.
Once you’ve got all these set up, it’s time to run the conversion script. Make sure you have all your .aud files in one folder and use the following command:
python converter.py --silk-decoder path/to/decoder path/to/your/audio/folder/
If you’re running on a Mac and followed my instructions exactly, you should be able to leave off the --silk-decoder argument as it assumes a default path of ./decoder.
The decoder should then spit out a folder timestamped with the current time and date with your audio files converted to .wav format. Note that the conversion can take a while. From here, you can convert these .wav files to .mp3 or any other format.
Reverse-engineering
So, how did I figure out how to convert these mysterious “.aud” files?
My first approach was to take a look to see if anybody had done this before. And they had! I found this link (this is an archive, the original website is gone). This link said that the .aud files were actually AMR files without their file header. This made it relatively easy to convert: just add #!AMR to the front of the files, and then run them through ffmpeg to convert to mp3. The site even provided a handy little Python script to do this conversion.
The problem was, when I tried this on my files, some of them worked, but the vast majority of them sounded like this:
Uh, that doesn’t sound good.
Looking deeper into it, I noticed that all the files that had worked with this sort of conversion were from before March of 2015 or so. This revealed the problem: WeChat had changed their audio file format. Old messages from before March 2015 were encoded in AMR, and new ones were in some other file format.
I looked at the newer files that hadn’t converted under a hex editor, and here’s where I found an important clue: every one of those files started with a single 02 byte followed by the string #!SILK_V3.
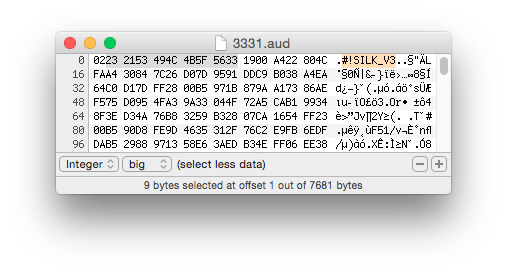
Back to Google I went with this information in hand. What I found was that this was the header for the SILK audio codec. This is a codec developed by Skype around 2009, and it’s the codec that powered Skype up until 2012 or so. In 2012, they made it open source, but some time between then and now, that repository and the code vanished from Skype’s official websites. Thanks to a useful blog post by Giacomo Vacca, I found a repository that did have the old SDK available for download.
So I downloaded the SDK, and tested it with a few files by stripping the 02 byte from the beginning of the file (presumably added by WeChat to denote that they were using their “version 2” audio format) and running it through the conversion tool in the SDK. And it worked!
Yes, that definitely is better.
After discovering this, I took the previous AMR-conversion script, and modified it: it now looks for the SILK header, converts the file using the SILK converter and ffmpeg if the header is there, and converts the file from AMR using just ffmpeg if it’s not. What you end up with is a folder full of .wav files, all nicely playable on whatever system you want, and easy to convert to another file format like mp3.
Parting words
All this would be unnecessary, of course, if WeChat simply allowed for an easy bulk export of audio messages. Unfortunately, like many other messaging apps, they don’t. And it’s a shame. Everyone who uses these types of apps has an immense amount of personal history locked away inside them: important talks with friends and family, warm messages from loved ones, conversations that are personally meaningful, and even ones that in the future may be historically meaningful. With such a closed-off data policy, we end up having to make herculean efforts like this in order to keep some of that history with us. And if the app or the company developing it dies, so too do the records.
If you’re a developer of one of these apps, please consider adding a small feature to extract these messages so we can keep them with us. Until then, we’ll have to keep being clever and working around them.
Thanks for reading this until the end! If this article was useful to you, please send me an email and let me know!